 Andy Hoagland | 7/6/2023
Andy Hoagland | 7/6/2023The internet is flooded with articles about large language models like ChatGPT, their potential, and what that may mean for the future of work. A chat application made large language models accessible to a wide audience, but the number of manual hours procuring high-quality data or the cloud costs to train these models is rarely discussed as often. These pre-trained models are for general tasks, in other words, think of these as having completed high school. The ability to fine-tune pre-trained models leveraging your own data with less resource investment is where the true potential of large language models lies.
Are we finally entering the golden age of AI? One analogy often brought up in technical circles is that it takes a 17-year-old approximately 20 hours of training to become proficient at driving a vehicle. There are some clear questions as to what defines proficiency, but when compared to the investment in time and resources for autonomous driving vehicles, it does put the question into a distinct perspective. The challenge to that view is that the 17-year-old has 17 years of experience interacting with the physical world equating to 99,280 waking hours (assuming an average of 8 hours of sleep per day). In other words, 17 years of continuous learning on a variety of subjects created the opportunity for only 20 hours of driving training to lead to proficiency. This analogy better represents the pre-trained large language models of today and their most efficient application.
A question remains: how to deploy such a powerful tool along with the infrastructure required to meet our own unique needs? The Washington Post recently wrote an article about the hidden costs. Link: ChatGPT has enormous hidden costs that could throttle AI development – The Washington Post. The article shared a quote from OpenAI CEO Sam Altman stating “There’s so much value here, it’s inconceivable to me that we can’t figure out how to ring the cash register on it.” How long has productizing large language models been a challenge? Few outside the technology world are aware that GPT-3, the precursor to GPT-3.5 behind the initial release of the ChatGPT interface, was first released on July 11, 2020.
Machine learning operations or MLOps were designed to productize ML capabilities at the enterprise level. Rather than insights living on the laptop of a data scientist, MLOps puts data science in production and at scale by incorporating the best practices from DevOps, a combination of development and IT operations. This adoption was made possible because the traditional ML cycle follows the cross-industry standard for data mining (CRISP-DM), a six-step process that has been around since the late 1990s. The challenge to overcome in the next few years is that large language models require an ecosystem that is still being developed in this nascent stage, new opportunities are emerging for those that do not write code.
A non-coding PM, whether a product or project manager, can now play a key role in fine-tuning large language models as the task is typically a no to low code operation. Feeding pre-trained models examples of what type of output users want makes the required task widely accessible, a dramatic change from non-coders contributions being limited to managing Scrum Ceremonies and Kanban boards. Stakeholders now have a new potential role beyond user acceptance testing in the traditional pre-production development cycle. In terms of people and process, this is a radical change to the DevOps and Agile frameworks which is one reason we use the term large language model operations to describe this workflow.
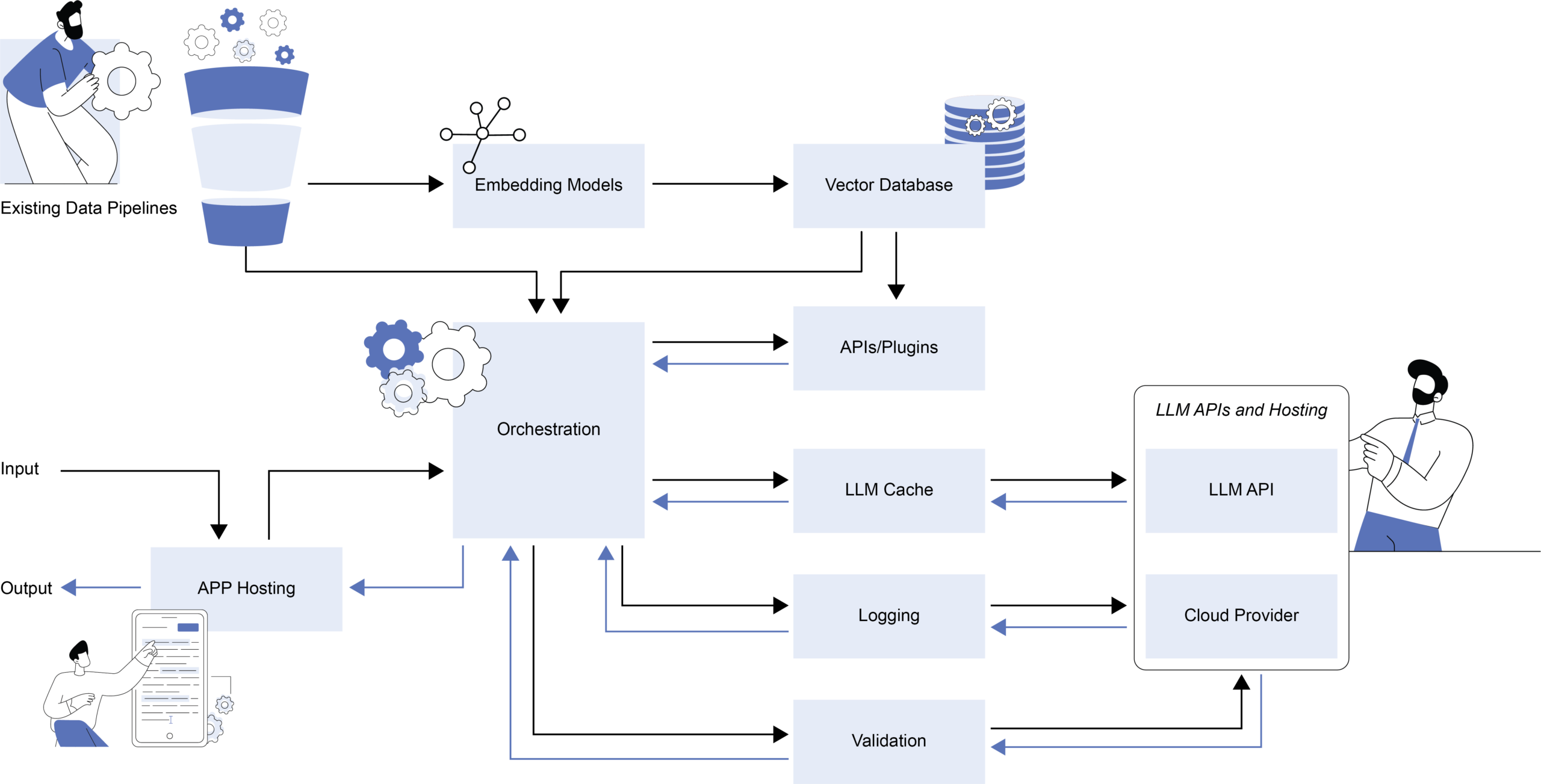
Large Language Model Operations Workflow
In addition to people and process changes, technological advancement goes beyond pre-trained models. New technology stack components are emerging like LangChain, a framework for orchestrating large language models, simplifying various API integrations necessary for deployment. Vector databases like Pinecone and Weaviate may be needed to reduce the computational burden but also come with their own cloud costs. Gradio is one of the machine learning tools for creating accessible interfaces to demo models while Hugging Face Spaces serves as a hosting community for large language model-powered apps. The technology stack will continue to evolve and change but the starting point of a pre-trained model and end point of a user-friendly interface will almost certainly remain constant. At Analytica, we continue to work with new technology stack components and incorporate MLOps best practices to build large language model-powered applications for our federal clients.
